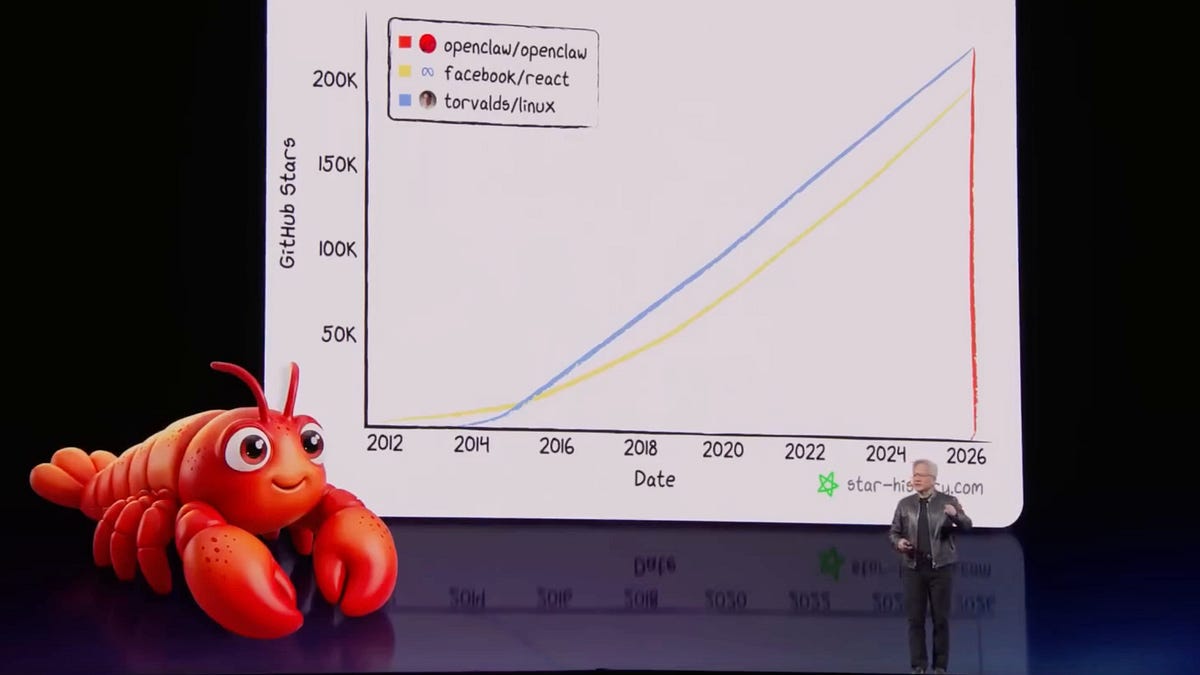
Key event: combined Vera Rubin + Groq architecture claims a ~35x improvement in throughput per megawatt versus NVIDIA Blackwell, signaling a shift toward inference-optimized hardware. The author argues inference demand has expanded ~1,000,000x over ~2 years (decode-phase memory-bandwidth bottleneck) and cites personal usage peaking at ~870 million tokens in one day and >200 million/day average recently. Implication: inference (and the 'OpenClaw' harness) will drive next-phase AI infrastructure investment, favoring memory-bandwidth-optimized chips and requiring firms to treat token consumption as a strategic productive input rather than a mere IT cost center.
The real economic pivot is organizational: firms that reclassify token consumption from an IT cost to a direct product input will unlock disproportionate operating leverage. Expect new KPIs (tokens-per-user-month, token-adjusted gross margin) to appear in board decks over the next 6–18 months; companies that optimize workflow orchestration around token efficiency should be able to widen gross margins by 10–30% on AI-native products without additional top-line growth. On the hardware and supply-chain side, the pressure point is memory bandwidth, interconnect and power density — not raw FLOPS. That shifts incremental value toward HBM suppliers, NIC/telemetry vendors, and server OEMs engineering for sustained sequential execution; their addressable market could grow >2x in 12–36 months while general-purpose GPU utilization profiles decelerate. A large secondary effect will be accelerated obsolescence of GPU-heavy refresh cycles, creating a used-GPU glut that temporarily depresses resale values and forces datacenter operators to stagger capital allocation. For incumbents, the runway to defend margins is narrow but real: software stacks, large-scale deployments and proprietary datasets impose switching costs that slow displacement even as specialized inference silicon improves. The immediate arbitrage window is in companies that buy at scale — they will be the first to convert lower inference unit costs into product differentiation and margin expansion. Tail risks that could reverse this path include a faster-than-expected consolidation around a single open inference standard, or regulatory limits on automated agent deployment that compress demand growth within 6–24 months.
AI-powered research, real-time alerts, and portfolio analytics for institutional investors.
Overall Sentiment
strongly positive
Sentiment Score
0.80
Ticker Sentiment