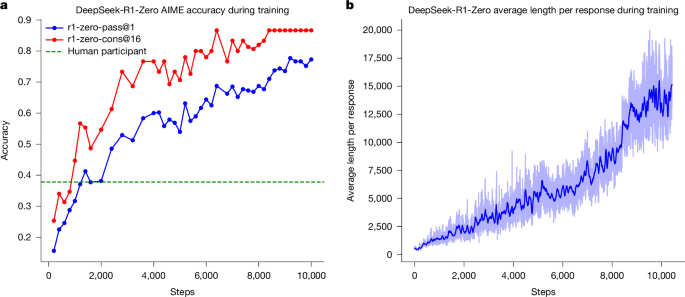
DeepSeek-R1 introduces a novel approach to large language model (LLM) reasoning, utilizing pure reinforcement learning (RL) to foster advanced problem-solving capabilities, such as self-reflection and dynamic strategy adaptation, with minimal reliance on human-annotated data. This method enabled DeepSeek-R1-Zero to achieve an impressive 86.7% accuracy on the AIME mathematics benchmark, significantly surpassing human performance, and demonstrating superior results in coding and STEM fields. The refined DeepSeek-R1 model further integrates this RL foundation with additional fine-tuning for improved general language generation and human alignment, with smaller distilled versions released to enhance accessibility and efficiency for advanced, autonomous AI applications.
DeepSeek has demonstrated a significant breakthrough in AI model training with its DeepSeek-R1 series, utilizing pure Reinforcement Learning (RL) to enhance reasoning capabilities without reliance on extensive human-annotated data. The core innovation lies in a rule-based reward system that incentivizes the model to develop emergent, advanced problem-solving strategies such as self-verification and reflection. This method has yielded state-of-the-art performance on verifiable tasks, with the DeepSeek-R1-Zero model achieving an 86.7% accuracy on the AIME 2024 mathematics benchmark, a result that significantly surpasses average human performance. While this technological advance is reflected in the strongly positive general sentiment, the more neutral sentiment attached to the DeepSeek entity itself suggests market uncertainty regarding its commercialization path. The company's strategy to release the models under an open-source MIT license could foster widespread adoption and position it as a leader in the open-source community, but it also introduces questions about direct monetization. The report transparently acknowledges current limitations, including suboptimal tool use, token inefficiency, and challenges in applying pure RL to tasks without reliable, rule-based verifiers, alongside a 'moderate' safety rating comparable to GPT-4o, which tempers the otherwise exceptionally strong technical results.
AI-powered research, real-time alerts, and portfolio analytics for institutional investors.
Request DemoOverall Sentiment
strongly positive
Sentiment Score
0.80
Ticker Sentiment